
Understand the history of data storage methods, the pros and cons of each approach, and which tool is right for your needs.
When seeking to understand more about data storage technologies and methods, a quick search yields thousands of results with a myriad of specific terminology. Being confronted with keywords like ‘Data Warehouses’, ‘NoSQL Databases’, ‘Knowledge Graphs’, and ‘Data Marts’ without any guidance can be intimidating!
To give you a hand in navigating the world of data storage, we have put together a small introduction to key concepts in the area, loosely organized in a timeline. By taking this trip down storage lane, you can grasp the connections between the different methods discussed, as well as their pros and cons.
Without further ado, let’s get into the history, which we divided into three phases.
Phase 1: Creating a Dedicated Data Storage System
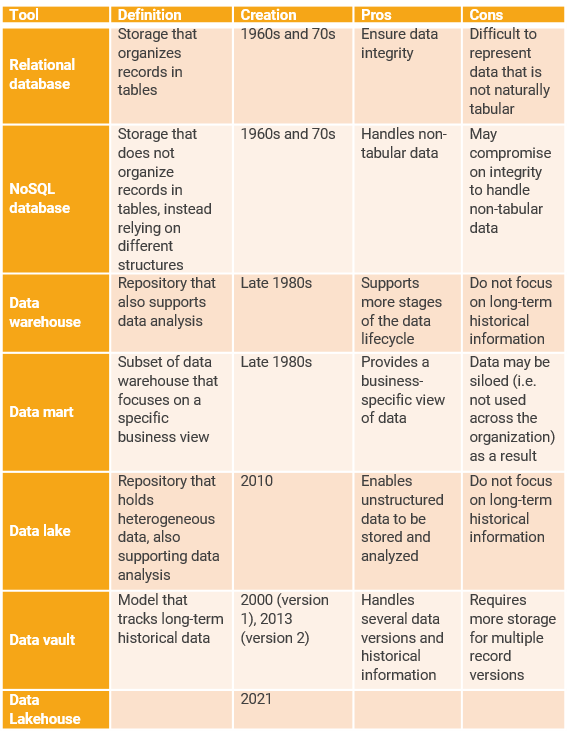
The initial phase in the evolution of data storage consisted of formalizing and implementing the concept of databases as dedicated systems for data storage. This happened around the 1960s and 70s, with the creation of two important concepts: relational databases, which organize data in a tabular fashion and enforce links between records, and NoSQL databases, which go the opposite route and do not model data as tables.
Pros
The solutions developed in this phase lay the foundation for the storage of various types of data. For instance, relational databases provide a relatively simple way of storing data that nonetheless ensures integrity and allows information to be easily queried. Meanwhile, NoSQL databases can store data with other structures (e.g. graphs).
Cons
Unfortunately, relational databases organize records in a strict way, which is not ideal for data that cannot naturally be represented in a tabular format. As for NoSQL databases, they may compromise on performance and integrity to be able to handle non-tabular data. Overall, databases alone focus on the storage of data, but do not provide many intuitive tools for the analysis stage.
Phase 2: Including Analytics Support
Once databases were cemented as a basic data repository standard, there was a push to expand the overall storage concept to also include analysis support. Eventually, this led to the creation of the Data Warehouse in the late 1980s. In addition to the centralized storage of data, this architectural model captures other aspects of the data lifecycle, such as the analysis stage (e.g. via the creation of consolidated operational or analytical reports and dashboards). Data Warehouses contain data about all aspects of a company, which means that they can be too general for the needs of particular departments. To address that, it is possible to create Data Marts, which are subsets (domain or business unit specific) within the Data Warehouse that show a particular view that is interesting to a specific scope.
In addition to analyzing large sets of consolidated data, many companies have the additional demand of separating the data as an asset from different perspectives of business contexts (e.g. aggregations or data quality rules. To address this need, the Data Vault modelling method was released in 2000, a second version followed in 2013. This method allows multi-tier architecture separating the historical data versioning from the applied business rules valid for a specific scope.
Data Vault enables the solid and scalable data architecture blueprint complies with FAIR data strategy as it offers the best re-usability of datasets (based on data governance/privacy) and tables (based on metadata structure). This can be obtained via the automation model we use in data integration. The ‘Enterprise’ Data Warehouse main objective is to be the consolidated data platform on enterprise/corporate level where the reuse of the data ‘both master and transactional’ and other FAIR data principles.
Data warehouses ensure that all the entries are structured and consolidated in a similar way for a unified analysis. While this is very useful in many scenarios, it does not account for cases in which we would like to store heterogeneous datasets. To support this scenario, Data Lakes were created in 2010. Unlike Data Warehouses, Data Lakes use a flat hierarchy, allowing various types of files and objects to be held and queried. Like Data Warehouses, Data Lakes provide the data platform needed for the creation of reports and advanced analytics.
Pros
The solutions developed in this phase go beyond just data storage, also supporting other stages of the data lifecycle. Namely, this phase focuses on providing tools for easily analyzing the data. For instance, Data Warehouses enable the functionality to develop consolidated operational and analytical reports. Meanwhile, Data Marts give specific departments within the company the ability to look at only the most relevant data subsets. Finally, Data Lakes allow companies to store and analyze heterogeneous and unstructured data.
Cons
While Data Warehouses, Data Marts, and Data Lakes enable the analysis of large datasets, each architectural pattern has its own points of strength and cannot cover the most common use-cases where both historical combined datasets and heterogeneous volumes of data are required for the business analytics.
Phase 3: Hybrid Approach: Data Lakehouse
The software company Databricks recently introduced the term ‘Lakehouse’ in their paper (Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics) which argues that a converging architectural pattern can be established combining Data Warehouses and Data Lakes. The idea of this hybrid approach is to capture the advantages of both architectures. Both relational structured data and unstructured volumes can be processed at the same time in the Data Lake within a robust Data Lakehouse technology stack (e.g. Azure Synapse Analytics, previously named Azure Data Warehouse).
Pros
The Data Lakehouse brings the benefits of the convergence between Data Warehouse and Data Lake.
With the multi-modal support in the Data Lakehouse, time-to market can be accelerated, supporting ACID transactions and streaming analytics can be achieved:
- Cross-Cloud Platforms (AWS, Azure, etc…)
- Hybrid Architecture (on-Cloud / on-Premise)
Cons
The Data Lakehouse is a relatively new cloud-based architecture, which needs more attention to implement the use cases with the proper cost management of cloud resources.
Which tool should you pick?
As you can see, there are many options for storing data. They were developed in different points in time to fulfil various user needs, as summarized in the following table.
Historical timeline

To decide on the best setup for your data, please contact the experts at OSTHUS. We will help you select or design the solution that makes the most sense in your context, allowing you to make the most of your data and to prepare for the future.



