
Not all data is created equal. Understand the different levels of data quality and how they can influence your organization.
In the race to leverage data as a valuable asset to the enterprise, we are constantly balancing the need for immediate access with the need to refine the information as much as possible. Ideally, we would like to extract the real nuggets of gold from our data, the ones that give us important strategic insights. However, it is also natural (and necessary!) to handle data at various stages of refinement on our way there.
So what does data look like at different levels of quality?
Data quality levels
A useful way of thinking about data quality is by splitting it into three distinct levels:
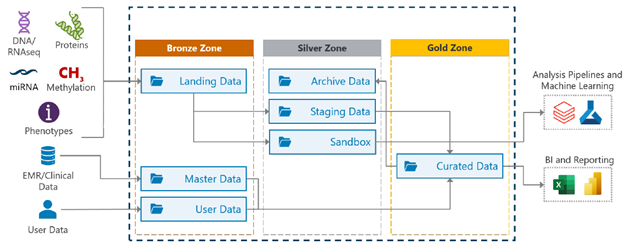
- Bronze: data at this level is raw and unmodified. It is often created or loaded from different heterogeneous source systems, and thus it is mostly useful in the short term with limited scope.
- Silver: this type of data has been filtered, cleansed, and structured before use, allowing it to be used in the medium to long term. As this data is somewhat standardized, it can be used by multiple team members and fit into a wider enterprise context.
- Gold: data at this level is processed until it is highly reusable and trustworthy. This data has been refined taking the needs of multiple team members from multiple parts of the organization into account. Generally, this data can be used for sophisticated analyses that increase the team’s understanding of the business.
How to improve overall data quality?
While many organizations have data at both ends of the spectrum, moving as much data as possible to the gold level (i.e. improving its quality) is a goal that will pay dividends for years to come. To do so, we rely on a number of strategies:
- Structure and integrate: the low-hanging fruit of data quality is standardization. Having cohesively structured datasets means that more people across the organization can consume the information from their own perspectives. Additionally, this structuring makes it easier to spot any potential issue in data points.
- Understand the user base: another effective measure is to understand how team members are consuming data, then tailor datasets to suit their needs. For example, if a subset of users habitually processes data in a specific way to produce a visualization, then giving them the ability to retrieve pre-processed information can significantly boost their productivity.
- Curate manually: while doing this for an entire dataset is not feasible, manually curating portions of the data can give the team an in-depth understanding of the overall data condition. Based on what we observe during this exercise, we can apply changes to data validation and structuring processes accordingly.
The pros of gold-level data
Once data transitions to a gold-level status, it offers some additional advantages to the organization. For instance, gold data has a high level of accuracy, which means that it can be used as a trusted input for training machine learning models and business intelligence tools. These techniques allow businesses to better understand their current state and to create segments for current behavior or forecasts that help inform decisions about the future.
Storing this heterogeneous data
As we can see, the data across the organization is handled and accessed by multiple user groups with varied needs. The question then becomes: how can we effectively store these heterogeneous data categories into a single, unified repository?
A potential answer is to employ a Data Lakehouse, which is a flexible repository that combines the scalability of a Data Lake with the solid integration power of a Data Warehouse. A Data Lakehouse has the advantage of allowing data to be organized in layers, which can be directly mapped to the bronze, silver, and gold quality categories above.


