
Learn in this blog post, why investing in a Data Warehouse to centralize information is your best bet to stay competitive in the digital transformation rush.
We all know that the pen-and-paper lab is on its way out, replaced by digital systems for collecting results, recording experiments, and presenting analysis work. This new environment, where scientists no longer have to enter all of the information manually, reduces the time spent on clerical tasks and provides the potential to boost research performance.
However, reaping these benefits depends on having a satisfactory answer to the following question: how do we effectively handle this influx of data from devices and experiments?
Handling data is tricky
Unfortunately, the answer to this question is not exactly as simple as “just store it all in a database”, for a number of reasons:
- Heterogeneous data: the data collected across the lab is typically heterogeneous, meaning that outputs from different sources are structured in particular ways and stored in various formats.
- Data quality: we need to check that the data is of reasonable quality, namely ensuring that the information is valid, consistent, accurate, etc.
- Auditing and compliance: the data must be auditable to comply with all of the regulatory requirements observed in the life science domain.
It quickly becomes obvious that putting in place a data storage solution that ticks all of these boxes is no child’s play!
Data Warehouses to the rescue
To meet all of these requirements, Life Science businesses are investing in Data Warehouses to store their information. A Data Warehouse is a system that centralizes data from various sources under one digital roof, providing integrated information that scientists can easily access and analyze. Here’s how a Data Warehouse delivers the goods:
- It handles heterogeneous data: a Data Warehouse combines data from heterogeneous sources, processing and integrating information so that it can be viewed in a unified way.
- It checks for data quality: as data is ingested, the Data Warehouse can validate whether it makes sense, e.g. checking its type and length. This catches any potential issues that would decrease the quality of the data.
- It is subject-oriented: a Data Warehouse organizes information in terms of concrete subjects (e.g. products, customers, vendors), making it easier for the organization to analyze the data that they find particularly interesting for their business.
- It is non-volatile and time-variant: data remains constant once it is added to the Data Warehouse, meaning that it is not erased over time. Instead, the Data Warehouse keeps track of the data’s history as it is updated.
- It includes data auditing: the Data Warehouse can be configured to offer audit trails, thus making it easier to meet regulatory demands.
Sounds promising, right? Read on to find out how to implement it.
How to build a Data Warehouse?
Data Warehouses are systems that take in heterogeneous data, restructure it, and make it available in different ways. As shown in Fig.1, the input is extracted from a number of original sources, (optionally) transformed in a staging area, and loaded into the Data Warehouse. The integrated data can then be queried or accessed through one of the available mechanisms.
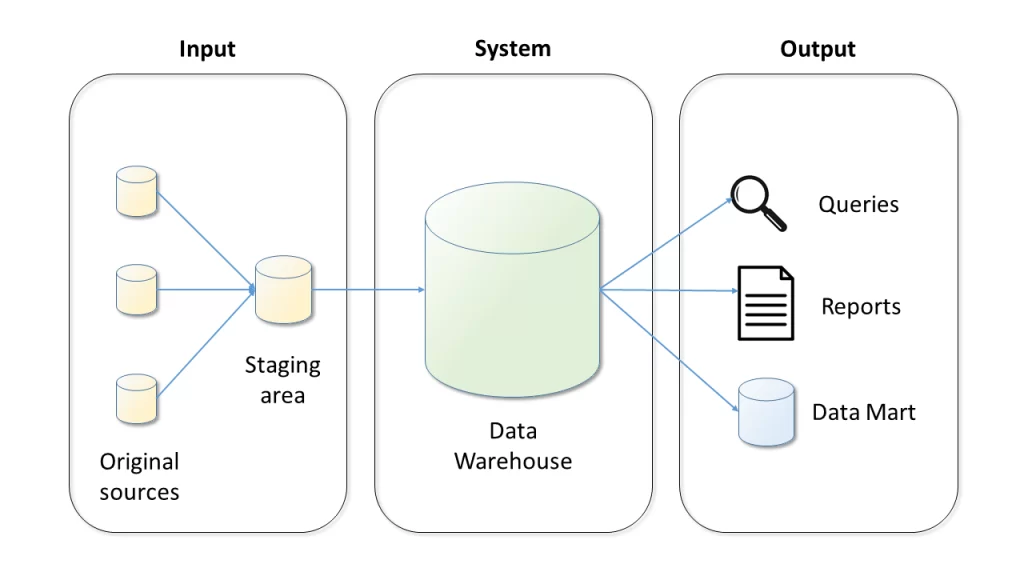
Figure 1: Data Warehouse Architecture
Data Warehouses are customizable to the needs of the enterprise, meaning that there is not a one-size-fits-all solution. For instance, this customization may take the form of a Data Mart, which is an interface for making Data Warehouse contents readily available to a specific department. Data Warehouses can also be built following different patterns, generally categorized as either ETL/ELT or near real-time streaming approaches.
ETL/ELT approaches (where the initials stand for Extract, Transform, and Load) focus on first extracting the data from the original source, then handling it further. For ETL, this means transforming the data into a standardized format and then loading it into the Data Warehouse. For ELT, on the other hand, the data is directly loaded and then modified within the Data Warehouse. ETL/ELT approaches have been used for decades, and they are ideal for processing data in batches.
Near real-time streaming approaches focus on updating the Data Warehouse frequently, as opposed to processing data in larger batches. This means that the information is obtained, manipulated, and loaded into the Data Warehouse at higher speeds. Near real-time streaming approaches are increasingly popular, since they are ideal for scenarios where it is important to act quickly on new data (e.g. image processing for drug discovery).
What’s in it for the users?
Ok, so it is clear that Data Warehouses hit the mark when it comes to infrastructure. But what are the benefits they provide to end users?
Here’s a few:
- Data-driven Decision Support System: when all the data is centralized, it becomes easy to test a hypothesis. This is great for making executive lab decisions based on facts, rather than gut feelings.
- Fast data retrieval: Data Warehouses are built to handle large amounts of data, so they can process complex queries and return large amounts of results without a hitch.
- Catalyst for high-quality research: with access to a Data Warehouse, scientists do not have to spend valuable time hunting down and cleaning data. Instead, they can focus on innovative research.
The team to build your Data Warehouse
A team of experts is required to build the Data Warehouse, including a business analyst to collect the lab’s specific requirements, a solution architect to design the required infrastructure, a DevOps engineer to implement the designed solution, and a project manager to coordinate the overall effort. If you need any support or guidance along the way, the experts at OSTHUS are happy to help.
Please contact us any time to discuss your specific needs.



